http://cafe.naver.com/pplus/220
[출처] [C특강] 배열을 사용한 효과적인 이중 링크드 리스트 구현|작성자 김은철
이중 링크드 리스트를 사용할 때 장점과 단점은 다음과 같다.
장점은,
1. 데이터의 삽입, 삭제가 빠르다.
단점은,
1. 데이터의 추가 시 메모리 할당이 발생하고, 삭제 시 메모리 해제가 발생한다.
2. 메모리 조각이 많이 발생한다.
3. 항상 처음부터 검색해야 한다.
이 중 단점 1,2를 배열을 사용해서 해결할 수 있다. 배열을 이용하면 메모리의 할당 및 해제가 자주 발생하지
않기 때문에 메모리 단편화를 줄일 수 있어, 효율적인 프로그램을 개발할 수 있다. 또한 메모리를 할당할 때
마다 발생하는 페이지 할당이 줄기 때문에 적은 메모리를 사용하게 된다. 이제는 링크드 리스트를 사용할 때
아래의 코드와 같이 배열을 사용하여 만들어 보자.
다음은 소스 코드이다.
#include <stdio.h> // printf, scanf
#include <stdlib.h> // malloc
#include <malloc.h> // malloc
#include <memory.h> // memset
struct tag_node
{
int data; // data
struct tag_node* next; // 4바이트 구조체 포인터
struct tag_node* prev; // 4바이트 구조체 포인터
};
typedef struct tag_node NODE;
typedef struct tag_node* PNODE;
struct tag_block
{
struct tag_block* block;
struct tag_block* next;
};
typedef struct tag_block BLOCK;
typedef struct tag_block* PBLOCK;
const int block_size = 100; // 배열의 크기
PNODE NewNode( PNODE prev, PNODE next );
void AddTail( int data );
void AddHead( int data );
int RemoveNode( PNODE pnode );
void PRINT();
void FREE();
PNODE HeadNode = NULL, TailNode = NULL, FreeNode = NULL;
PBLOCK NodeBlock = NULL;
void main( void )
{
int data = 1;
while( data )
{
scanf( "%d", &data );
AddTail( data );
}
PRINT();
FREE();
}
PNODE NewNode( PNODE PrevNode, PNODE NextNode )
{
PNODE Node;
if( !FreeNode )
{
int i;
PNODE pnode; // 1차원 배열의 포인터
PBLOCK pblock;
// BLOCK + block_size 만큼 1차원 배열을 할당
// 메모리 구조는 다음과 같이 한 개의 BLOCK 구조체와
// 여러 개의 NODE 구조체로 구성된다.
// | BLOCK(8바이트) | NODE * block_size |
pblock = (PBLOCK)malloc( sizeof(BLOCK) + sizeof(NODE) * block_size );
// BLOCK의 첫 8바이트를 가지고 NODE 블럭을 관리한다.
if( !NodeBlock )
{
NodeBlock = pblock;
NodeBlock->block = pblock;
NodeBlock->next = NULL;
}
else
{
pblock->next = NodeBlock;
NodeBlock = pblock;
NodeBlock->block = pblock;
}
// FreeNode를 BLOCK의 크기인 8만큼 더한 위치로 설정
FreeNode = (PNODE)(pblock + 1);
memset( FreeNode, 0, sizeof(NODE) * block_size );
pnode = FreeNode;
// 각 배열 요소의 next를 그 다음 배열 요소로 설정
// 맨 끝의 배열 요소는 memset 함수에 의해 자동으로 NULL이 됨
for( i=0; i<block_size-1; i++ )
{
pnode[i].next = &pnode[i+1];
}
}
Node = FreeNode;
FreeNode = FreeNode->next; // 다음 Node로 이동
Node->prev = PrevNode; // 이전 노드 설정
Node->next = NextNode; // 다음 노드 설정
return Node;
}
void AddTail( int data )
{
PNODE pnode;
pnode = NewNode( TailNode, NULL );
pnode->data = data;
if( !HeadNode )
{
HeadNode = TailNode = pnode;
return;
}
TailNode->next = pnode;
pnode->prev = TailNode;
TailNode = pnode;
}
void AddHead( int data )
{
PNODE pnode;
pnode = NewNode( TailNode, NULL );
pnode->data = data;
if( !HeadNode )
{
HeadNode = TailNode = pnode;
return;
}
HeadNode->prev = pnode;
pnode->next = HeadNode;
HeadNode = pnode;
}
int RemoveNode( PNODE pnode )
{
PNODE PrevNode;
PNODE NextNode;
PrevNode = pnode->prev;
NextNode = pnode->next;
// 제거되는 노드가 HeadNode인 경우
if( pnode == HeadNode )
{
HeadNode = HeadNode->next;
}
// 제거되는 노드가 TailNode인 경우
if( pnode == TailNode )
{
TailNode = TailNode->prev;
}
// 제거되는 노드의 이전 노드가 있는 경우
if( PrevNode )
{
PrevNode->next = NextNode;
}
// 제거되는 노드의 다음 노드가 있는 경우
if( NextNode )
{
NextNode->prev = PrevNode;
}
// FreeNode의 맨 앞으로 연결
pnode->next = FreeNode;
FreeNode = pnode;
return pnode->data;
}
void PRINT()
{
PNODE pnode = HeadNode; // 맨 앞의 링크드 리스트 위치로 설정
while( pnode )
{
printf( "%d ", pnode->data );
pnode = pnode->next; // 다음 리스트의 번지값으로 pnode의 값을 변경
}
}
void FREE()
{
PBLOCK pblock;
pblock = NodeBlock;
while( pblock )
{
NodeBlock = pblock->next;
free( pblock );
pblock = NodeBlock;
}
}
위 코드에서 NewNode()라는 함수는 아래의 그림과 같이 BLOCK 구조체와 NODE 구조체를 생성하는 함수이다.
이 함수는 내부적으로 malloc() 함수에 의해 BLOCK 구조체 한 개, NODE 구조체 100개를 생성한다.
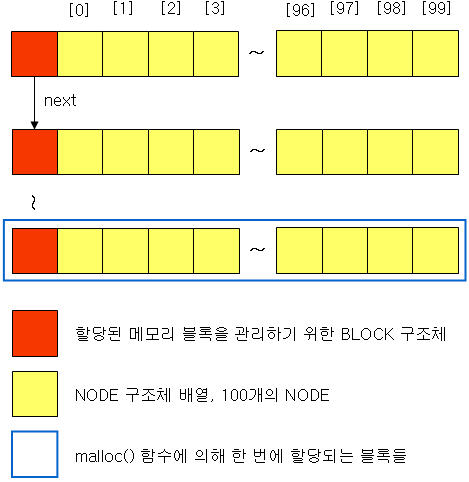
NODE가 위와 같이 한 번에 100개(또는 1000개도 가능) 생성되면, 100개의 NODE를 다 사용할 때까지
더는 메모리 할당이 발생하지 않는다. 이 것은 메모리 단편화를 없앨 수 있는 방법이기도 하다. 만약
NODE를 필요할 때마다 할당한다면 무수히 많은 메모리 조각이 생길 것이고, 결국 작은 메모리 조각을
할당하고 관리하기 위해 좀 더 많은 메모리가 필요해 진다.
[출처] [C특강] 배열을 사용한 효과적인 이중 링크드 리스트 구현|작성자 김은철
'프로그래밍' 카테고리의 다른 글
| 1차원 배열 다수를 2차원 배열로 (0) | 2011.08.18 |
|---|---|
| ZeroMemory, memset, 구조체={0} 의 차이 (0) | 2011.07.30 |
| C로 구현한 Queue (0) | 2011.07.18 |
| 구조체 동적 배열 (0) | 2011.07.16 |
| 동적배열 (0) | 2011.07.16 |